Einführung
Die zunehmende Verbreitung von Deepfakes – künstlich generierten oder manipulierten Medien, insbesondere im Audio-Bereich – stellt eine Herausforderung für die digitale Sicherheit dar. Gefälschte Stimmen können in Nachrichten, rechtlichen Kontexten oder persönlichen Kommunikationen schwerwiegende Folgen haben. Hinter der Erkennung solcher Manipulationen steht oft fortschrittliche KI-Technologie, wobei das LightGBM-Modell (Light Gradient Boosting Machine) eine zentrale Rolle spielt. In diesem ausführlichen Blogbeitrag beleuchte ich die Stärken und Funktionsweise von LightGBM, analysiere zwei begleitende Diagramme – eine Confusion Matrix und eine Lernkurve – und interpretiere ihre Bedeutung. Zudem gehe ich auf technische Details ein, einschließlich GPU- und OpenCL-Unterstützung, und stelle verschiedene Anwendungsoptionen vor, darunter Tools wie der „Deepfake Audio Scanner“.
Überblick: Was ist LightGBM?
LightGBM ist eine effiziente Implementierung von Gradient Boosting, einer maschinellen Lernmethode, die Entscheidungsbäume kombiniert, um Klassifikations- und Regressionsaufgaben zu lösen. Es zeichnet sich durch hohe Geschwindigkeit, Skalierbarkeit und geringe Speicheranforderungen aus, was es ideal für die Analyse großer Datensätze macht. Im Kontext der Deepfake-Erkennung wird LightGBM oft genutzt, um Audios auf Manipulationen hin zu untersuchen, basierend auf einem segmentbasierten Ansatz mit zahlreichen Features. Die bereitgestellten Diagramme – eine Confusion Matrix und eine Lernkurve – geben Einblicke in die Leistungsfähigkeit des Modells, während Tools wie der „Deepfake Audio Scanner“ nur eine von vielen Anwendungsmöglichkeiten darstellen.
Die Benutzeroberfläche: Ein Beispiel für Anwendung
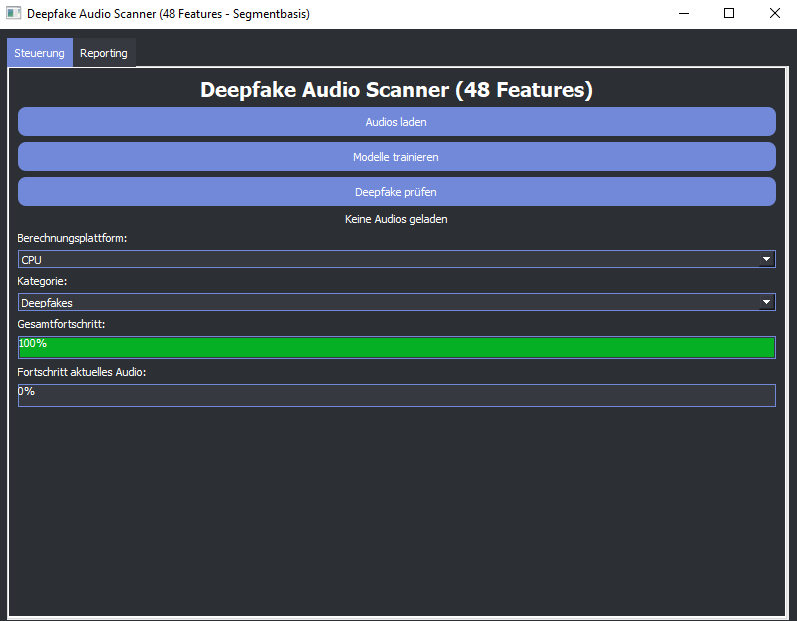
Ein Beispiel für die praktische Nutzung von LightGBM ist die Benutzeroberfläche des „Deepfake Audio Scanner“. Das erste Bild zeigt diese Oberfläche mit dem Titel „Deepfake Audio Scanner (48 Features) – Segmentbasis“, was auf 48 Merkmale hinweist, die vermutlich akustische und statistische Eigenschaften umfassen. Die Oberfläche bietet:
- Funktionen: Drei blaue Buttons – „Audios laden“, „Modelle trainieren“ (mit GPU/OpenCL-Unterstützung) und „Deepfake prüfen“ – ermöglichen die Interaktion mit dem Modell.
- Status: „Keine Audios geladen“ zeigt, dass das Tool noch nicht aktiv ist. Ein Dropdown für die „Berechnungsplattform“ zeigt „CPU“, obwohl GPU- und OpenCL-Optionen integriert sind.
- Fortschritt: Ein grüner Balken bei 100 % deutet auf eine abgeschlossene Initialisierung hin, während der Fortschritt des aktuellen Audios bei 0 % liegt, da keine Dateien geladen sind.
Das moderne Design mit dunklem Hintergrund und hellen Akzenten (Blau, Grün) verdeutlicht, wie LightGBM in einer benutzerfreundlichen Anwendung eingesetzt werden kann. Dieses Tool ist jedoch nur eine von vielen Möglichkeiten – LightGBM kann auch in anderen Softwarelösungen oder eigenständigen Analysen genutzt werden.
Analyse der Modellleistung: Die Confusion Matrix
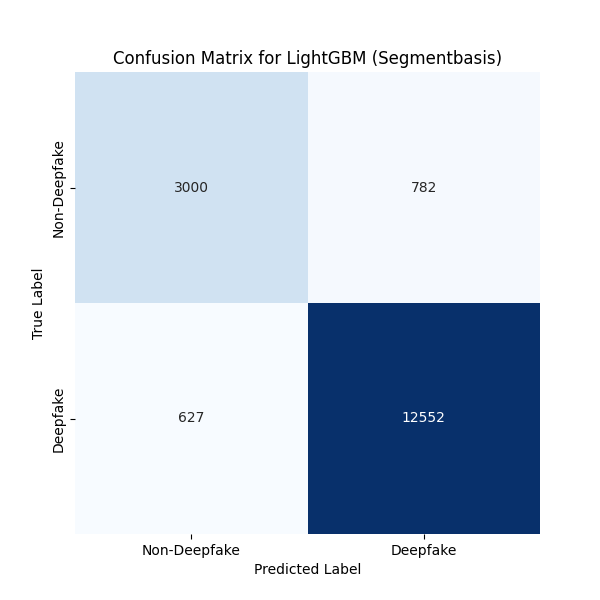
Die zweite Abbildung zeigt eine Confusion Matrix, die die Klassifikationsleistung von LightGBM bewertet. Sie vergleicht die tatsächlichen (True Label) und vorhergesagten (Predicted Label) Klassen „Non-Deepfake“ und „Deepfake“:
- True Negatives (3000): 3000 Fälle, in denen Non-Deepfakes korrekt erkannt wurden.
- False Positives (782): 782 Fälle, in denen Non-Deepfakes fälschlicherweise als Deepfakes klassifiziert wurden.
- False Negatives (627): 627 Fälle, in denen Deepfakes als Non-Deepfakes fehldetektiert wurden.
- True Positives (12552): 12552 Fälle, in denen Deepfakes korrekt identifiziert wurden.
Interpretation der Confusion Matrix
- Sensitivität: Die hohe Anzahl an True Positives (12552) zeigt eine starke Fähigkeit von LightGBM, Deepfakes zu erkennen. Die Sensitivität (Recall) ist hoch, was bedeutet, dass manipulierte Audios selten übersehen werden.
- Spezifität und Präzision: Die 782 False Positives und 627 False Negatives deuten darauf hin, dass die Spezifität (Korrektklassifikation echter Audios) und Präzision (Anteil korrekter Deepfake-Klassifikationen) verbessert werden können. False Positives könnten echte Audios fälschlich als manipuliert markieren, was in sensiblen Anwendungen problematisch ist.
- Gesamtleistung: LightGBM zeigt eine solide Leistung, insbesondere bei der Deepfake-Erkennung, aber die Fehlklassifikationen (False Positives und Negatives) sind Aspekte, die optimiert werden sollten.
Diese Matrix verdeutlicht, warum LightGBM in Deepfake-Erkennung beliebt ist – seine Fähigkeit, komplexe Muster zu erkennen, ist beeindruckend, auch wenn die Balance zwischen Sensitivität und Spezifität weiter verfeinert werden könnte.
Lernverlauf des Modells: Die Lernkurve
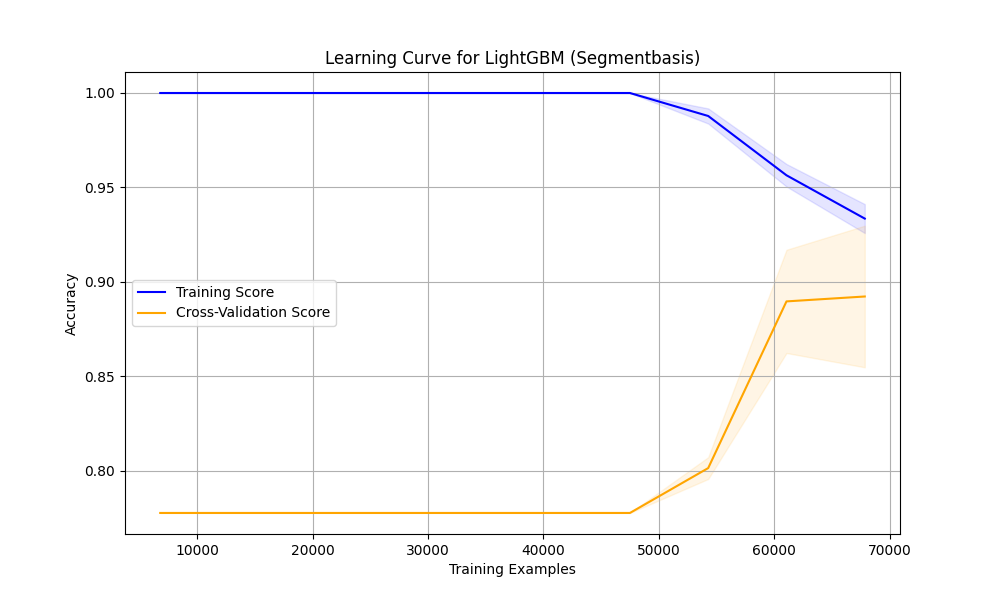
Das dritte Bild zeigt die Lernkurve von LightGBM, mit der Anzahl der Trainingsbeispiele (0 bis 70.000) auf der X-Achse und der Genauigkeit (Accuracy) von 0.80 bis 1.00 auf der Y-Achse. Zwei Kurven sind dargestellt:
- Training Score (blau): Startet bei 1.0 und fällt leicht auf etwa 0.95.
- Cross-Validation Score (orange): Steigt von 0.80 auf ca. 0.90 bei 40.000 Beispielen und nähert sich dem Training-Score.
Interpretation der Lernkurve
- Training-Score: Der anfängliche Wert von 1.0, der auf 0.95 abfällt, deutet auf eine leichte Überanpassung (Overfitting) hin. LightGBM passt sich zunächst zu stark an die Trainingsdaten an, stabilisiert sich jedoch mit mehr Daten.
- Cross-Validation-Score: Der Anstieg von 0.80 auf 0.90 zeigt eine effektive Generalisierung. Das Modell lernt Muster, die auch auf neuen Daten funktionieren, was durch GPU- und OpenCL-Beschleunigung beschleunigt werden kann.
- Generalisierung: Der schrumpfende Abstand zwischen den Kurven ist ein Zeichen für gute Generalisierung, ohne Überanpassung.
- Plateau-Effekt: Ab 50.000 Beispielen flacht die Validierungskurve ab, was darauf hinweist, dass zusätzliche Daten nur marginale Verbesserungen bringen. Die Genauigkeit von 0.95 ist ein starkes Ergebnis.
Die Lernkurve unterstreicht die Anpassungsfähigkeit von LightGBM, die mit GPU-OpenCL-Unterstützung noch effizienter genutzt werden kann.
Technische Grundlagen von LightGBM
LightGBM ist eine optimierte Version von Gradient Boosting, die Entscheidungsbäume effizient kombiniert. Es nutzt Histogrambasierte Algorithmen, um die Trainingszeit zu verkürzen, und unterstützt parallele Verarbeitung, was mit GPU- und OpenCL-Technologien noch verstärkt wird. Die 48 Features könnten umfassen:
- Akustische Merkmale: Frequenzspektren, Tonhöhenverläufe, Sprachmuster.
- Statistische Indikatoren: Rauschverhältnisse, Signal-zu-Rausch-Verhältnis.
- Segmentbasierte Merkmale: Unterschiede zwischen Audioabschnitten.
Die GPU- und OpenCL-Unterstützung ermöglicht parallele Berechnungen auf CPUs und GPUs, was die Verarbeitung großer Datensätze beschleunigt. OpenCL (Open Computing Language) ist besonders flexibel, da es auf verschiedenen Hardwareplattformen läuft, während GPUs die Rechenleistung für komplexe Modelle steigern.
Anwendungsoptionen für LightGBM
LightGBM ist vielseitig einsetzbar und wird in verschiedenen Kontexten genutzt, darunter Tools wie der „Deepfake Audio Scanner“. Hier sind einige detaillierte Anwendungsbereiche:
- Medien und Journalismus:
- LightGBM könnte Audios von Interviews auf Manipulationen prüfen, mit GPU-Beschleunigung für Echtzeitanalyse großer Archive.
- Faktenchecker könnten Deepfakes in viralen Clips identifizieren, wobei OpenCL parallele Verarbeitung unterstützt.
- Sicherheitssektor:
- In der Strafverfolgung könnte LightGBM Aufnahmen analysieren, mit GPU-Unterstützung für schnelle Bearbeitung großer Fallakten.
- Militärische Kommunikationen könnten mit OpenCL in Echtzeit auf Integrität geprüft werden.
- Unterhaltungsindustrie:
- Filmproduktionen könnten Audios auf Deepfakes prüfen, wobei GPUs die Analyse großer Datenmengen beschleunigen.
- Musiklabels könnten Songs mit OpenCL effizient auf gefälschte Vocals untersuchen.
- Forschung und Entwicklung:
- Wissenschaftler könnten LightGBM nutzen, um Deepfake-Techniken zu analysieren, mit GPU-Beschleunigung für komplexe Modelle.
- KI-Experten könnten es weitertrainieren, wobei OpenCL parallele Datenverarbeitung optimiert.
- Privatnutzung:
- Einzelpersonen könnten Audionachrichten prüfen, mit GPU-Unterstützung für schnelle Analysen.
- Hobbyisten könnten historische Aufnahmen analysieren, mit OpenCL für große Archive.
- Unternehmenssicherheit:
- Unternehmen könnten Meetings prüfen, mit GPU-Beschleunigung für große Datenmengen.
- Callcenter könnten Anrufe mit OpenCL parallel analysieren.
- Bildung und Training:
- Universitäten könnten LightGBM in Kursen nutzen, mit GPU-Unterstützung für Trainingsdemonstrationen.
- Sprachtherapeuten könnten mit OpenCL Sprachdaten effizient verarbeiten.
- Politik und Wahlen:
- Wahlkampfteams könnten Audios prüfen, mit GPU-Unterstützung für Echtzeitanalysen.
- Regierungsbehörden könnten Reden mit OpenCL schnell analysieren.
- Gesundheitswesen:
- Ärzte könnten Patientenaufnahmen prüfen, mit GPU-Beschleunigung für Diagnosen.
- Forschungsinstitute könnten mit OpenCL komplexe Sprachmuster analysieren.
- Finanzwesen:
- Banken könnten Audios von Transaktionen prüfen, mit GPU-Unterstützung für Betrugserkennung.
- Versicherungen könnten Anrufaufzeichnungen mit OpenCL validieren.
Stärken und Grenzen von LightGBM
Stärken:
- Effizienz: Schnelle Trainingszeiten durch Histogrambasierte Algorithmen und GPU/OpenCL-Unterstützung.
- Skalierbarkeit: Geeignet für große Datensätze, wie die Lernkurve zeigt.
- Robustheit: Hohe Sensitivität bei Deepfake-Erkennung (12552 True Positives).
- Generalisierung: Gute Anpassung an neue Daten, wie die Cross-Validation-Score von 0.90 verdeutlicht.
Grenzen:
- Overfitting: Leichte Überanpassung im Training-Score (1.0 auf 0.95), die optimiert werden könnte.
- Fehlerquote: 782 False Positives und 627 False Negatives zeigen Verbesserungsbedarf.
- Datenabhängigkeit: Die Lernkurve zeigt, dass mehr Daten die Genauigkeit steigern könnten, aber das Plateau bei 0.95 erreicht ist.
- Hardware-Anforderungen: Obwohl GPU/OpenCL unterstützt wird, könnten ältere Systeme Schwierigkeiten haben.
Mögliche Erweiterungen
- Optimierte GPU/OpenCL-Integration: Feinabstimmung für maximale Beschleunigung.
- Feature-Engineering: Neue Merkmale könnten die Genauigkeit steigern.
- Echtzeitanalyse: Live-Überprüfung mit GPU/OpenCL.
- Multilinguale Unterstützung: Anpassung an verschiedene Sprachen.
- Cloud-Integration: Analyse über Cloud-Services mit GPU-Support.
Fazit
LightGBM ist ein leistungsstarkes KI-Modell, das sich durch Effizienz und Robustheit auszeichnet, wie die Confusion Matrix (12552 True Positives) und die Lernkurve (0.95 Genauigkeit) zeigen. Die integrierte GPU- und OpenCL-Unterstützung macht es besonders geeignet für datenintensive Anwendungen, während die leichte Überanpassung und Fehlerquote Verbesserungspotenzial bieten. Tools wie der „Deepfake Audio Scanner“ sind nur eine von vielen Anwendungsmöglichkeiten – von Medien über Sicherheit bis hin zu Bildung und Forschung reicht das Spektrum. Mit weiteren Entwicklungen könnte LightGBM eine Schlüsselrolle in der Bekämpfung digitaler Manipulationen übernehmen, und es bietet Entwicklern sowie Nutzern eine spannende Grundlage für innovative Projekte.
Schreibe einen Kommentar