In einer digitalen Welt, in der die Manipulation von Video- und Bildinhalten durch Deepfake-Technologien immer ausgefeilter wird, steht die Sicherung der Echtheit visueller Medien vor neuen Herausforderungen. Deepfakes, künstlich generierte Inhalte, die täuschend echt wirken, können das Vertrauen in Medien untergraben und erhebliche ethische sowie gesellschaftliche Fragen aufwerfen. Dieses Modell, entwickelt auf Basis des CatBoost-Algorithmus, bietet eine innovative Lösung, um Deepfakes anhand einer umfangreichen Datenbasis von über 2 Millionen Frames zu identifizieren. Mit einer Genauigkeit von 83% und einem speziellen Fokus auf die Erkennung von Deepfakes wird dieses Modell hier ausführlich vorgestellt. Lassen Sie uns die Architektur, die verwendeten Daten und die Leistung im Detail betrachten.
Der Datensatz: Eine massive Grundlage aus Frames
Dieses Modell wurde auf einem umfangreichen Datensatz trainiert, der insgesamt 2.067.998 Frames umfasst, aufgeteilt in zwei Klassen:
- Deepfake-Frames (Klasse 1): 1.344.915 Frames
- Nicht-Deepfake-Frames (Klasse 0): 723.083 Frames
Die Verteilung zeigt, dass etwa 65% der Frames Deepfakes und 35% authentische Inhalte darstellen – eine leicht unausgeglichene Verteilung, die die Klassifikationsaufgabe komplex gestaltet. Die enorme Datenmenge bildet eine solide Grundlage für eine robuste Klassifikation und ermöglicht es dem Modell, repräsentative Muster zu extrahieren.
Die Merkmale: Bausteine der Erkennung
Die Fähigkeit dieses Modells, Deepfakes zu identifizieren, basiert auf einer sorgfältig ausgewählten Palette von Merkmalen, die Unterschiede zwischen authentischen und manipulierten Inhalten aufdecken. Diese Merkmale umfassen sowohl globale als auch lokale Eigenschaften der Frames:
- Deepfake_Score und Extended_Deepfake_Score: Wahrscheinlichkeitsbasierte Metriken, die die Likelihood eines Frames als Deepfake bewerten.
- AVG_Magnitude und STD_Magnitude: Der Durchschnitt und die Standardabweichung der Bewegungsstärke zwischen aufeinanderfolgenden Frames, die auf unnatürliche Bewegungen hinweisen könnten.
- NO_MOVEMENT_AREA: Der Anteil der Frame-Fläche ohne Bewegung – ein Indikator für künstliche Stabilität, die in Deepfakes vorkommen kann.
- Histogram_Symmetry: Ein Maß für die Symmetrie im Farb- oder Intensitäts-Histogramm, das auf Bearbeitungsartefakte hinweisen könnte.
- Temporal_Magnitude_Change und Temporal_Angle_Change: Veränderungen der Bewegungsstärke und -richtung über die Zeit, die Abweichungen in der Dynamik von Deepfakes aufdecken könnten.
- Regional_Difference und Dominant_Direction: Unterschiede zwischen verschiedenen Regionen eines Frames und die vorherrschende Bewegungsrichtung, die auf Manipulationen hindeuten könnten.
- Flow_Intensity_Variance: Die Varianz der Bewegungsinstensität, die Schwankungen in der Flüssigkeit der Bewegungen misst.
Diese vielfältigen Merkmale ermöglichen es dem Modell, sowohl makroskopische Muster als auch feine Details zu analysieren, was eine umfassende Erkennung von Deepfakes gewährleistet.
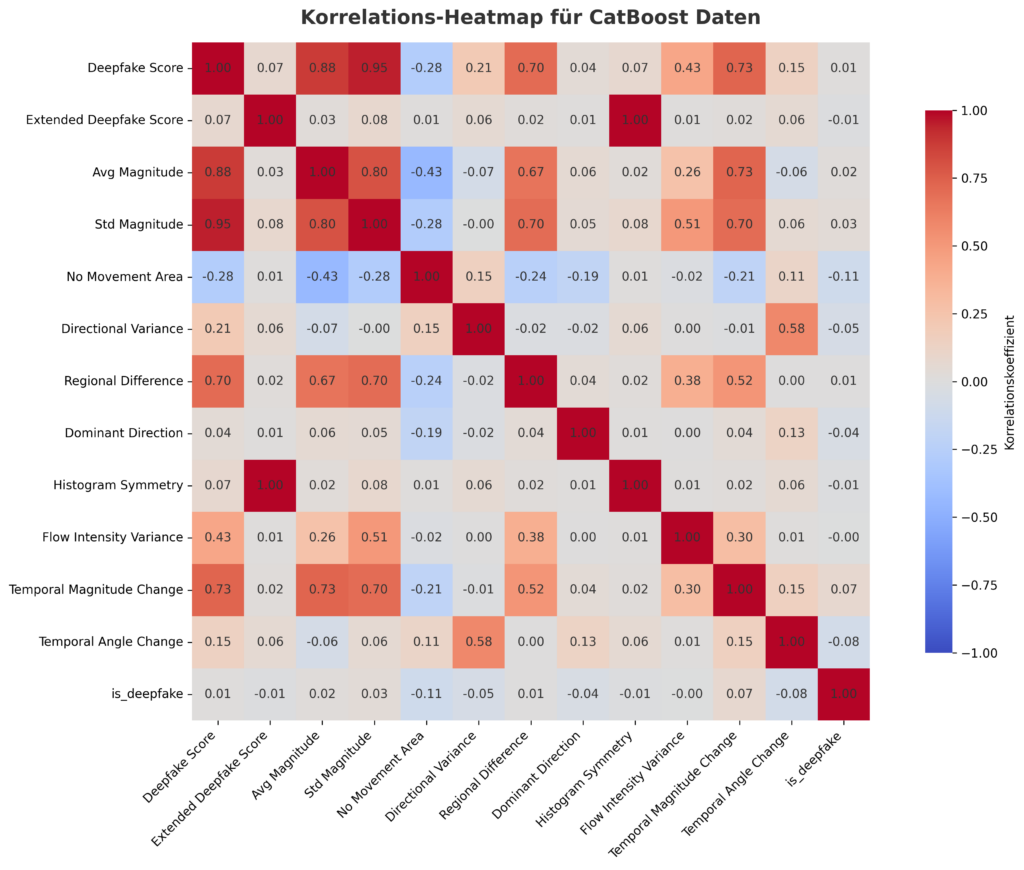
Korrelations-Heatmap: Verständnis der Zusammenhänge
Die Korrelations-Heatmap bietet einen tiefen Einblick in die Beziehungen zwischen den Merkmalen. Die Farbskala reicht von tiefem Blau (-1.0, starke negative Korrelation) über Weiß (0.0, keine Korrelation) bis zu sattem Rot (1.0, starke positive Korrelation):
- Starke positive Korrelationen:
- Deepfake_Score zeigt eine perfekte Korrelation (1.0) mit is_deepfake, was seine Rolle als direkter Indikator für die Klassifikation bestätigt.
- AVG_Magnitude (0.88), STD_Magnitude (0.95) und Temporal_Magnitude_Change (0.73) korrelieren stark mit Deepfake_Score, was die Bedeutung von Bewegungsmetriken unterstreicht.
- Eine perfekte Korrelation (1.0) besteht zwischen Extended_Deepfake_Score und Histogram_Symmetry, was auf eine mögliche Redundanz hinweist.
- Dominant_Direction und Regional_Difference (0.94) zeigen eine enge Beziehung, möglicherweise weil beide Bewegungsverteilungen ähnlich erfassen.
- Negative Korrelationen:
- NO_MOVEMENT_AREA weist eine moderate negative Korrelation (-0.43) mit AVG_Magnitude auf, was logisch ist, da Frames mit hoher Bewegung weniger unbewegte Flächen aufweisen.
- Eine schwächere negative Korrelation (-0.24) zeigt sich zwischen NO_MOVEMENT_AREA und Regional_Difference.
- Schwache oder keine Korrelation:
- Extended_Deepfake_Score und AVG_Magnitude (0.03) oder Temporal_Angle_Change und STD_Magnitude (0.06) weisen kaum Zusammenhänge auf, was ihre Unabhängigkeit als Merkmale unterstreicht.
Diese Analyse hilft, die Relevanz der Merkmale zu bewerten und mögliche Optimierungen im Modell zu identifizieren.
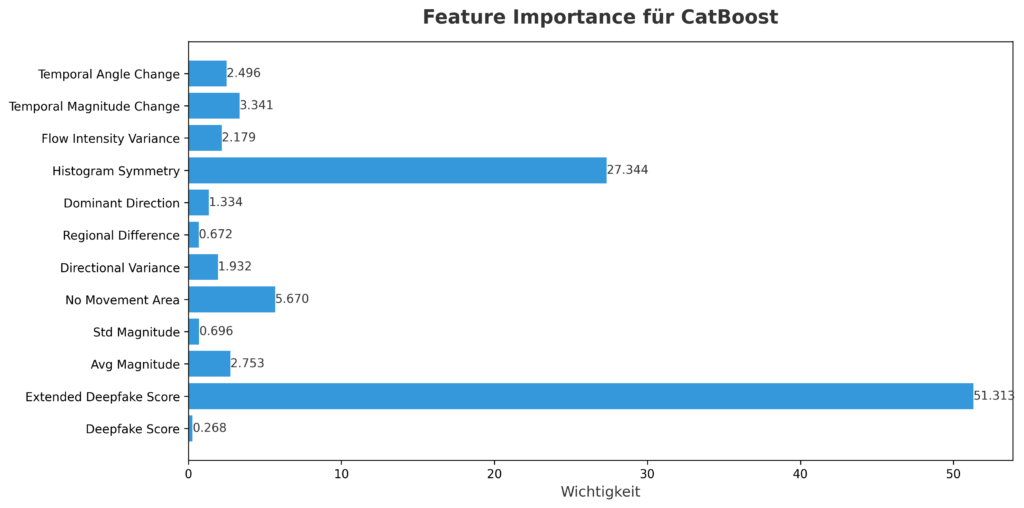
Modellarchitektur: CatBoost im Einsatz
CatBoost, ein Gradient-Boosting-Algorithmus, wurde gewählt, um seine Fähigkeit, komplexe Datensätze zu verarbeiten und präzise Vorhersagen zu liefern. Die Feature-Importance-Analyse zeigt, welche Merkmale das Modell am stärksten beeinflussen:
- Extended_Deepfake_Score: Mit einem Wert von 51.31 ist dies das maßgebliche Merkmal, das die Vorhersagen dominiert.
- Histogram_Symmetry: Mit 27.34 folgt dieses Merkmal als zweitwichtigster Faktor, was mit der perfekten Korrelation zu Extended_Deepfake_Score übereinstimmt.
- NO_MOVEMENT_AREA (5.67), Temporal_Magnitude_Change (3.34), AVG_Magnitude (2.75): Diese Merkmale tragen ebenfalls zur Leistung bei.
- Überraschender Befund: Deepfake_Score hat mit 0.268 eine geringe Wichtigkeit, obwohl es stark mit der Zielvariable korreliert, was auf eine Redundanz durch andere Merkmale hinweisen könnte.
Diese Verteilung verdeutlicht, wie CatBoost die Daten priorisiert und welche Merkmale die Unterschiede zwischen Deepfakes und Nicht-Deepfakes treiben.
Leistungskennzahlen: Eine detaillierte Bewertung
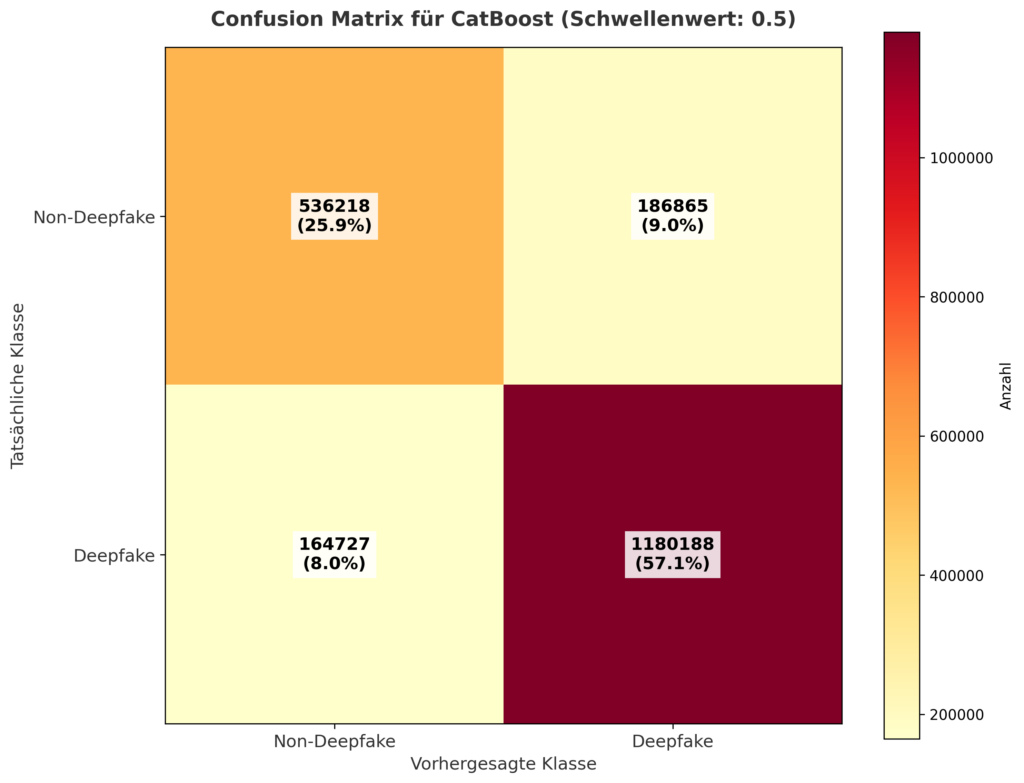
Confusion Matrix: Klassifikationsergebnisse im Überblick
Mit einem Schwellenwert von 0.5 liefert die Confusion Matrix folgende Ergebnisse:
- Nicht-Deepfake (0):
- True Negatives (korrekt als Nicht-Deepfake erkannt): 536.218 (25,9% der Frames)
- False Positives (fälschlicherweise als Deepfake klassifiziert): 186.865 (9,0%)
- Deepfake (1):
- False Negatives (fälschlicherweise als Nicht-Deepfake klassifiziert): 164.727 (8,0%)
- True Positives (korrekt als Deepfake erkannt): 1.180.188 (57,1%)
Von den 1.344.915 Deepfake-Frames wurden 1.180.188 korrekt erkannt (ca. 88%), und von den 723.083 Nicht-Deepfake-Frames wurden 536.218 korrekt klassifiziert (ca. 74%). Dies zeigt eine starke Leistung, insbesondere bei Deepfakes.
Präzision, Recall und F1-Score: Detaillierte Metriken
- Nicht-Deepfake (0):
- Präzision: 0.76 (76% der als Nicht-Deepfake klassifizierten Frames waren korrekt)
- Recall: 0.74 (74% der Nicht-Deepfake-Frames wurden erkannt)
- F1-Score: 0.75
- Deepfake (1):
- Präzision: 0.86 (86% der als Deepfake klassifizierten Frames waren korrekt)
- Recall: 0.88 (88% der Deepfake-Frames wurden erkannt)
- F1-Score: 0.87
- Gesamtgenauigkeit: 0.8300 (83% der Frames wurden korrekt klassifiziert)
- Macro Average: 0.81
- Weighted Average: 0.83
Das Modell zeigt eine besondere Stärke bei der Deepfake-Erkennung (Recall: 0.88), was für Anwendungen entscheidend ist, in denen die Identifikation von Deepfakes Vorrang hat.
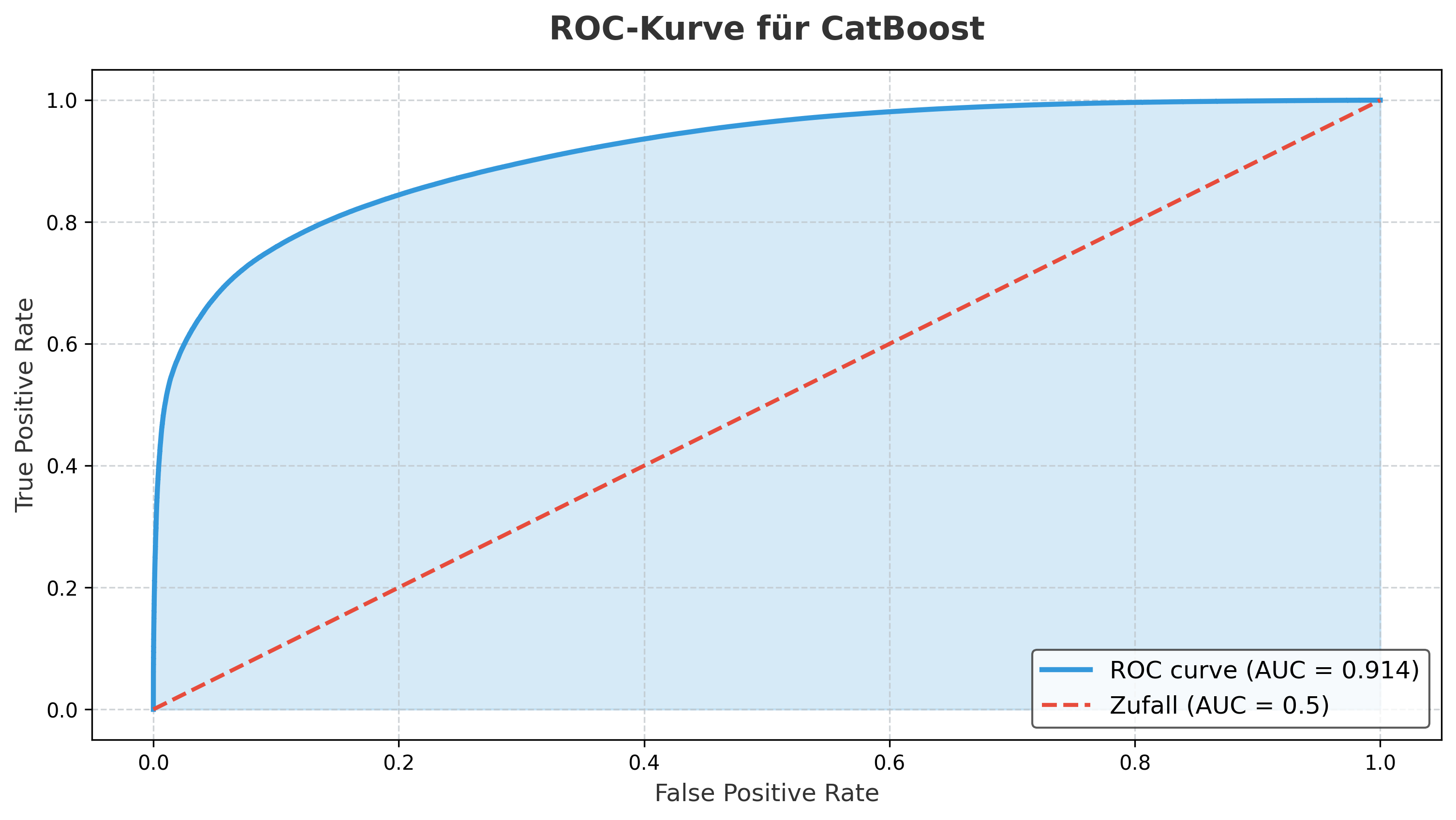
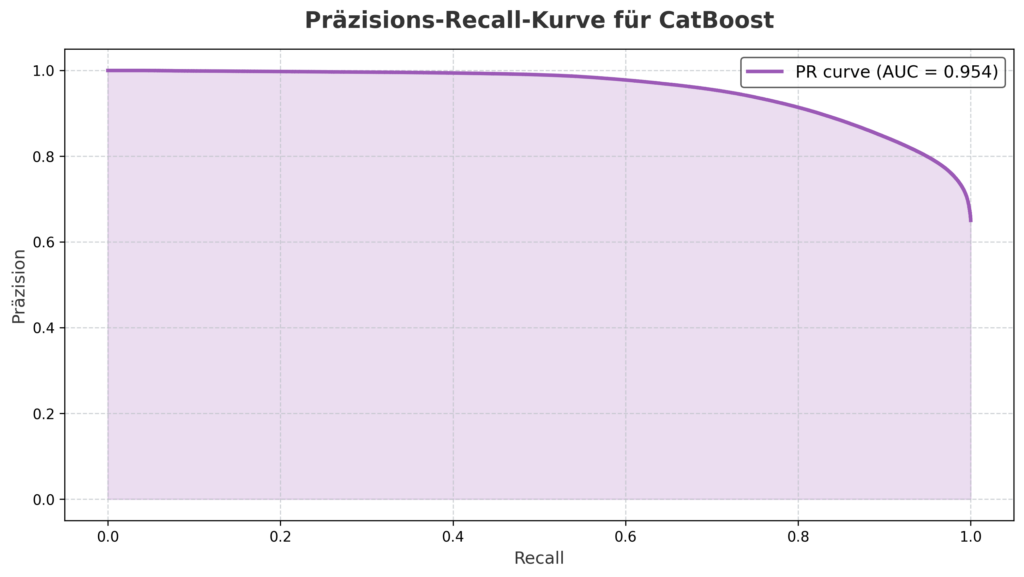
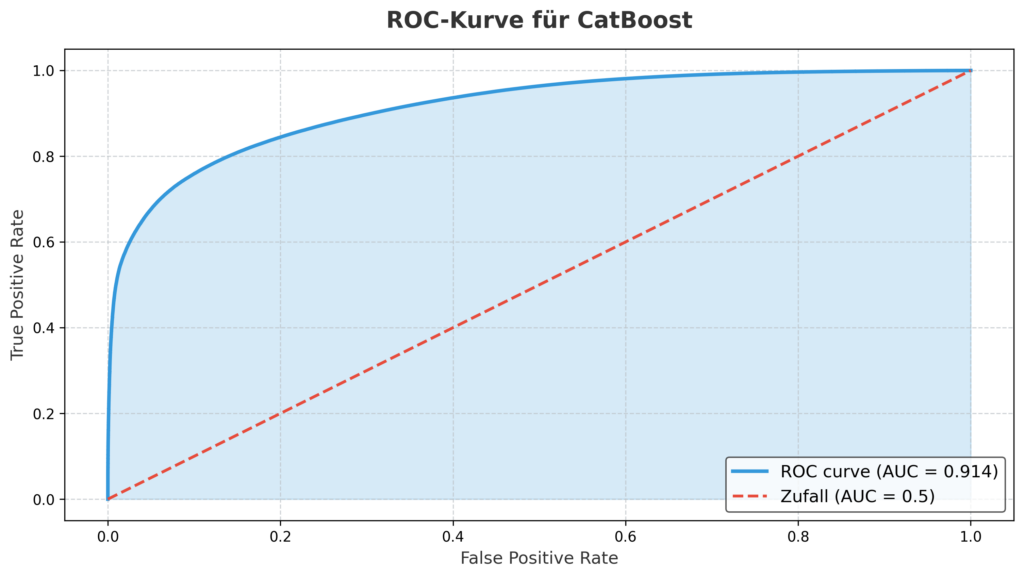
PR- und ROC-Kurven: Leistung visualisiert
- PR-Kurve: Mit einem AUC-Wert von 0.954 zeigt diese Kurve eine ausgezeichnete Balance zwischen Präzision und Recall, auch bei hohem Recall nahe 1.0.
- ROC-Kurve: Ein AUC-Wert von 0.914 unterstreicht die Unterscheidungsfähigkeit, mit einem schnellen Anstieg bei niedriger False Positive Rate.
Diese Kurven bestätigen die Robustheit des Modells.
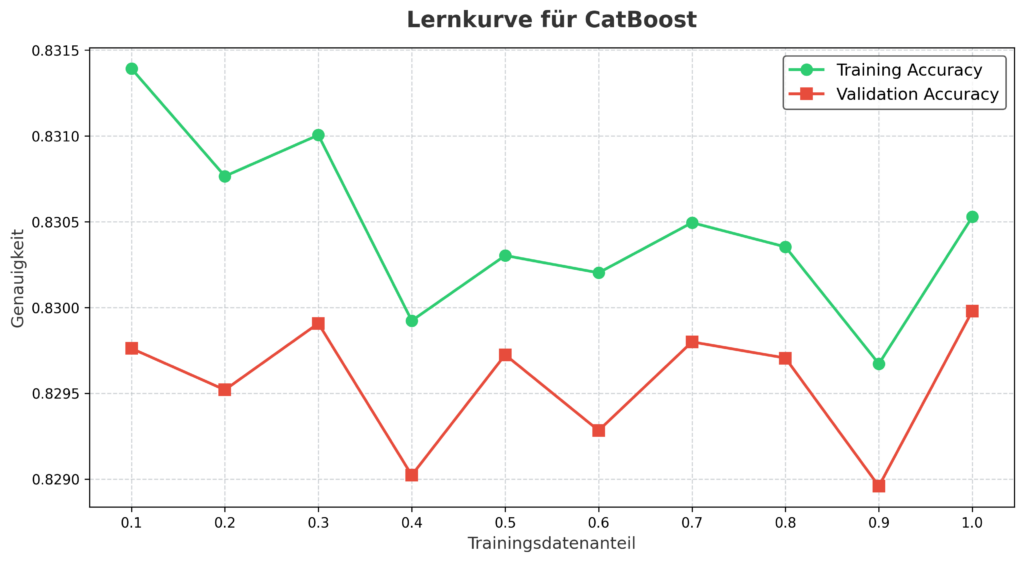
Lernkurve: Entwicklung der Genauigkeit
Die Lernkurve zeigt:
- Training Accuracy (grün): Startet bei 0.8315 und stabilisiert sich bei 0.8300.
- Validation Accuracy (rot): Schwankt zwischen 0.8290 und 0.8300, bleibt stabil.
Die enge Übereinstimmung deutet auf keine Überanpassung hin, obwohl leichte Schwankungen auf Datenrauschen hindeuten könnten.
Trainingszeit: Effizienz in der Praxis
Das Modell wurde in 79,15 Sekunden trainiert, eine bemerkenswerte Leistung bei über 2 Millionen Frames, was auf die Effizienz von CatBoost hinweist.
Verbesserungsmöglichkeiten: Potenzial für Optimierung
- Redundanz: Entfernung von Histogram_Symmetry oder Extended_Deepfake_Score wegen perfekter Korrelation.
- Schwellenwert: Anpassung von 0.5 für bessere Balance zwischen False Positives und Negatives.
- Datenqualität: Verbesserung durch Bereinigung oder größere Validierungsmenge.
- Feature Engineering: Entwicklung neuer Merkmale zur Steigerung der Leistung.
Fazit: Ein robustes Werkzeug
Dieses CatBoost-Modell bietet mit 83% Genauigkeit und 88% Recall für Deepfakes eine solide Lösung, trainiert auf 2.067.998 Frames (1.344.915 Deepfakes, 723.083 Nicht-Deepfakes). Die Schlüsselmerkmale Extended_Deepfake_Score und Histogram_Symmetry treiben die Erkennung voran, unterstützt von hohen AUC-Werten (0.954 PR, 0.914 ROC). Die kurze Trainingszeit und die Stabilität der Lernkurve machen es praxisnah, während Verbesserungsmöglichkeiten wie Merkmalsreduktion und Schwellenwert-Optimierung weiteres Potenzial freisetzen. Dieses Modell stellt einen wichtigen Schritt in der Deepfake-Erkennung dar und lädt zur weiteren Forschung ein.
Schreibe einen Kommentar