
Eine Fallstudie zum Training großer KI-Modelle
Ausgangspunkt: Das Ziel
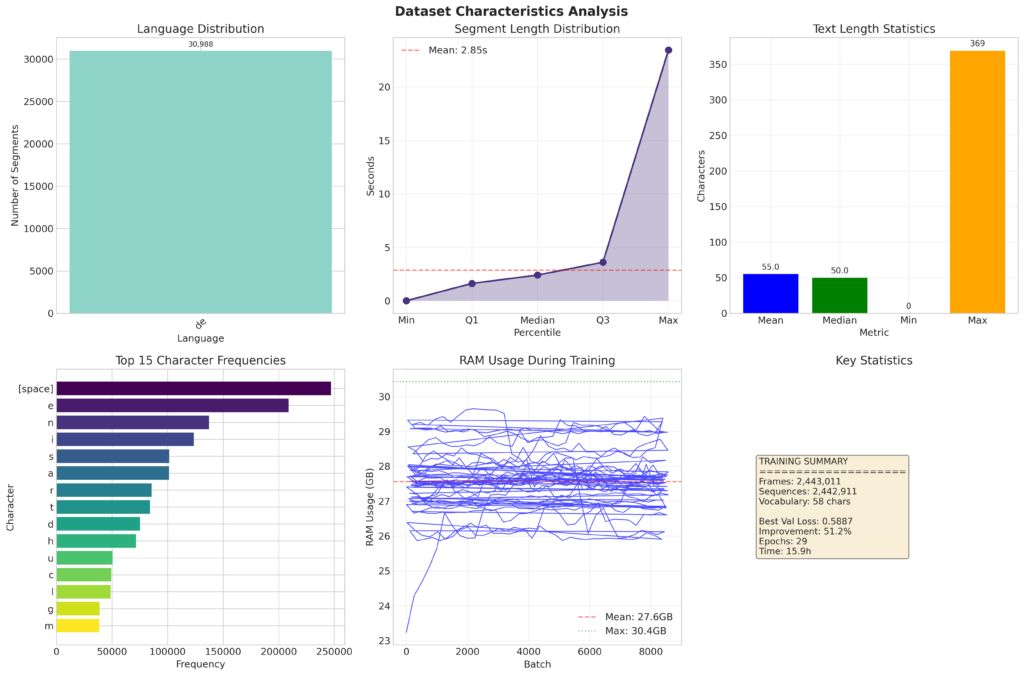
Das Projekt verfolgte ein klar definiertes Ziel: die Entwicklung eines robusten Lip-Reading-Modells (automatisches Lippenlesen) auf Basis eines massiven Datensatzes mit über 2,44 Millionen Einzelbildern (Frames). Der Fokus lag nicht nur auf der finalen Performance, sondern auch auf der Analyse des Trainingsverlaufs und der dabei auftretenden Dynamiken.
Die Trainingsdaten im Überblick
- Datensatzumfang: 2,44 Millionen Frames
- Sequenzlänge: 100 Frames pro Trainingsbeispiel
- Eingabedimension: 1.404 Landmark-Punkte pro Frame
- Vokabular: 85 Zeichen (überwiegend deutsch)
- Batch-Größe: 256
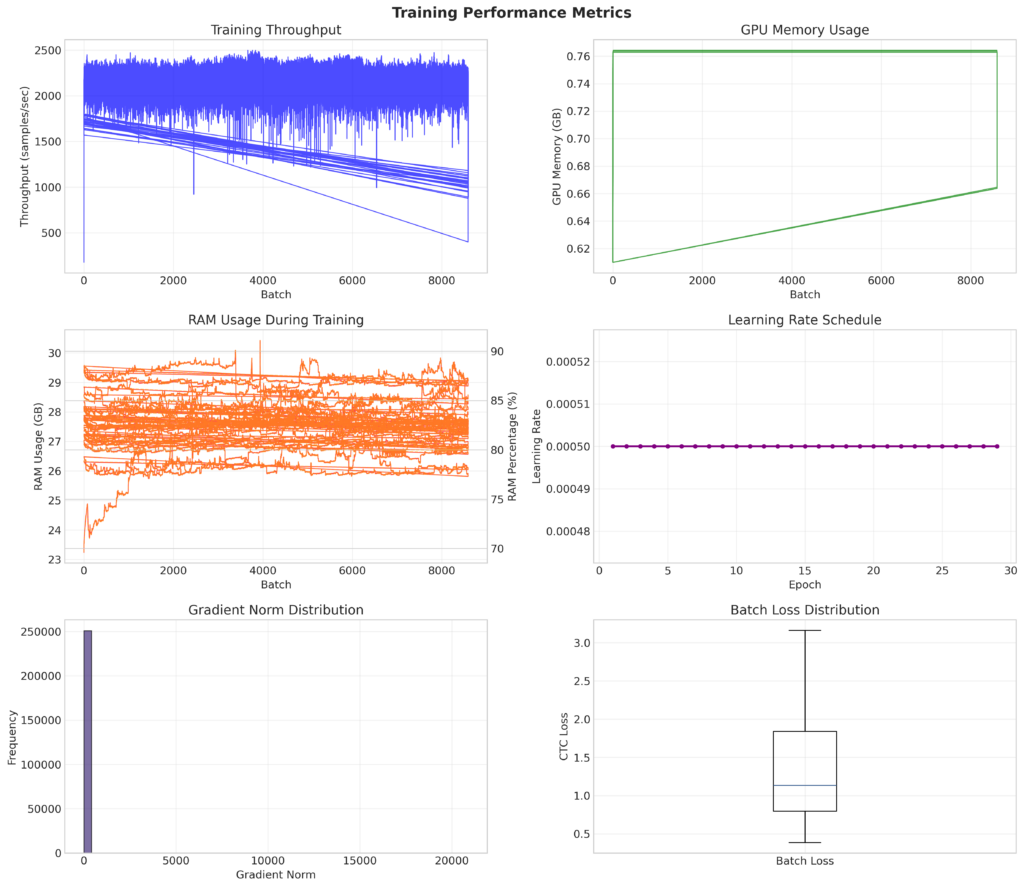
- Hardware: Training auf GPU mit etwa 27 GB RAM-Auslastung
Der Trainingsverlauf: Ein Bergsteiger mit Absturzgefahr
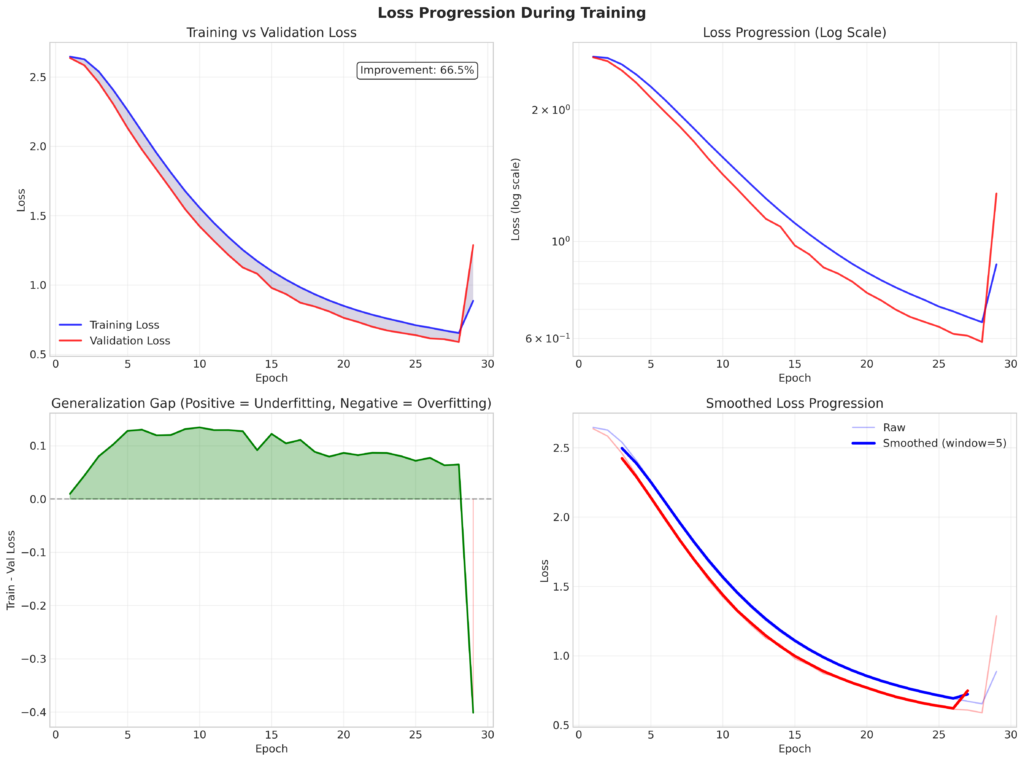
Das Training über insgesamt 31 Epochen lieferte ein äußerst anschauliches Bild für die Herausforderungen beim Optimieren komplexer neuronaler Netze.
- Stetiger Aufstieg zum Optimum (Epochen 1-28):
Das Modell verbesserte sich kontinuierlich und erreichte in Epoche 28 den besten Validierungs-Loss von 0,5887. Die Decodierung von Text aus den visuellen Daten funktionierte in vielen Fällen bereits erstaunlich präzise, wie Stichproben zeigten. - Der Peak und der Beginn der Instabilität (Epoche 29):
Unmittelbar nach Erreichen des Optimums zeigten die Metriken erste Anzeichen von Instabilität. Der Loss stieg leicht an, ein klassisches Zeichen dafür, dass das Modell – angetrieben durch eine konstante Lernrate – begann, im Loss-Landscape über das gefundene Minimum hinaus zu „explorieren“. - Katastrophaler Modellkollaps (Epochen 30-31):
Die Situation eskalierte in den folgenden Epochen. Der CTC-Loss verdoppelte sich nahezu auf Werte über 2,0. Noch deutlicher wurde das Problem bei der Decodierung:- Aus dem Satz „da haben ja manche das gefühl“ wurde „da habe bag manother“.
- Der Satz „und es interessiert mich“ degenerierte zu „un de.“.
Analyse der Ursachen
Der scharfe Abstieg nach einem so klaren Optimum ist für die Forschung hochinteressant. Mögliche Erklärungen sind:
- Gradient Explosion: Die Gradienten (Richtungsvektoren für die Anpassung der Modellgewichte) wurden instabil und „explodierten“ in ihrer Größe, was zu unkontrollierten, großen Updates der Parameter führte.
- Instabilität des Optimierers: Der verwendete AdamW-Optimierer könnte durch extreme Gradienten in einen Zustand geraten sein, in dem seine internen Momenta-Schätzungen korrumpiert wurden.
- Aggressive Exploration: Die feste, relativ hohe Lernrate von 5e-04 ermöglichte es dem Modell nach dem Finden eines lokalen Minimums nicht, sich dort zu stabilisieren, sondern trieb es in instabile Regionen des Parameterraums.
Wissenschaftliche Erkenntnisse und Implikationen
Dieses Experiment liefert mehr als nur ein trainiertes Modell; es bietet wertvolle Einblicke:
- Die Bedeutung des Early-Stoppings: Das protokollierte Scheitern unterstreicht die kritische Rolle von Abbruchkriterien. Ein automatischer Stopp nach z.B. 10 Epochen ohne Verbesserung hätte das optimale Modell der Epoche 28 zuverlässig gesichert.
- Vorsicht bei der Lernrate: Der Fall zeigt, dass eine konstante Lernrate nach Erreichen eines Plateaus oder Optimums riskant sein kann. Adaptive Scheduler oder manuelle Reduzierung sind für stabile Langzeittrainings essenziell.
- Loss-Landscapes sind komplex: Besonders bei anspruchsvollen Aufgaben wie dem Lip-Reading können die Fehlerlandschaften („Loss Landscapes“) komplexe Topologien mit steilen Abhängen aufweisen, die ein Modell leicht hinabstürzen lassen können.
- Der Wert der Dekodierungsanalyse: Die Live-Decodierung von Textproven war ein entscheidendes Diagnosetool. Während der Loss allein die Richtung anzeigte, machten die sinnentstellten Ausgaben das Ausmaß des Kollapses sofort sichtbar.
Fazit und Ausblick
Das Training wurde nach Epoche 31 bewusst abgebrochen. Das Modell aus Epoche 28 (Validation Loss: 0,5887) steht als solides Ergebnis der ersten, erfolgreichen Trainingsphase zur Verfügung.
Die nächsten Schritte könnten sein:
- Feintuning vom Checkpoint Epoche 28 mit einer deutlich reduzierten Lernrate (z.B. 1e-05).
- Implementierung eines robusten Learning-Rate-Schedulers, der die Rate bei Plateau automatisch reduziert.
- Verstärktes Gradient-Clipping, um extreme Updates zu verhindern.
- Analyse der Gewichte und Gradienten während des Kollapses, um die exakte Ursache zu isolieren.
Dieses Projekt demonstriert eindrucksvoll, dass das Training moderner KI-Modelle nicht nur eine Frage der Rechenleistung, sondern auch des sorgfältigen Monitorings und der robusten Steuerung dynamischer Optimierungsprozesse ist. Der dokumentierte Kollaps ist dabei kein Misserfolg, sondern eine wertvolle Datenquelle, die zum besseren Verständnis des Trainingsverhaltens solcher Systeme beiträgt.


Schreibe einen Kommentar