In der heutigen digitalen Welt wird die effiziente Verarbeitung von Dokumenten immer wichtiger. Ich habe eine Python-basierte Anwendung entwickelt, die OCR (Optical Character Recognition), Dokumentenverarbeitung und semantische Suche in einem benutzerfreundlichen Interface vereint. In diesem Artikel möchte ich die Funktionsweise und Besonderheiten dieser Lösung vorstellen.
Die Kernfunktionen der Anwendung
Die Anwendung bietet mehrere zentrale Funktionen:
- Textextraktion aus Bildern und PDFs: Mittels Tesseract OCR können Texte aus verschiedenen Dateiformaten extrahiert werden, darunter PDFs, PNGs, JPGs und mehr. Die Anwendung verbessert die Bildqualität automatisch durch Kontrastanpassung und Schärfung, bevor die OCR durchgeführt wird.
- Dokumentenverarbeitung: Textdateien, CSV, Excel und HTML können direkt verarbeitet und indiziert werden. Die Anwendung nutzt fortgeschrittene Textverarbeitungstechniken, um die Inhalte für die spätere Suche aufzubereiten.
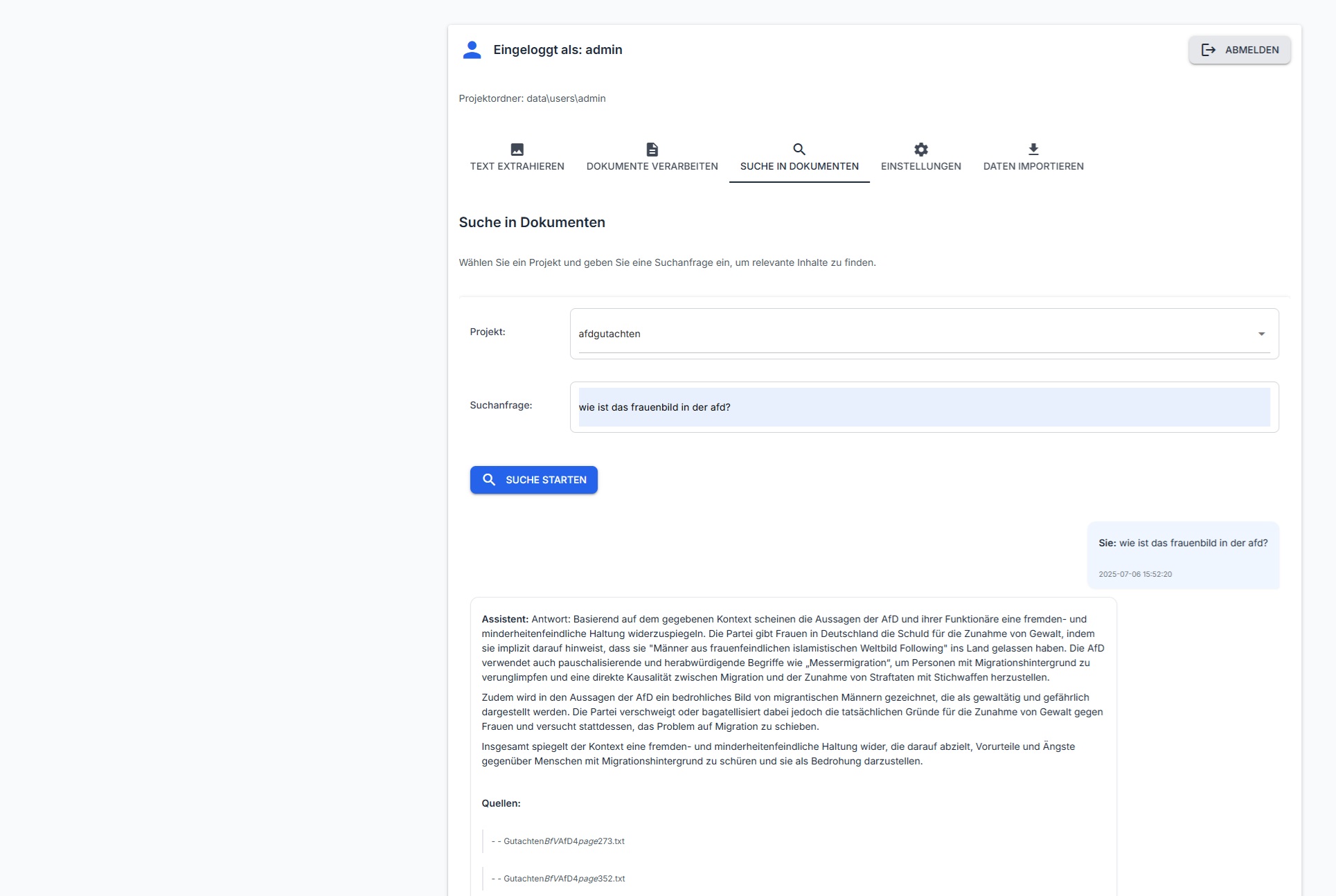
- Semantische Suche: Durch den Einsatz von Sentence-Transformers und dem HNSW-Algorithmus (Hierarchical Navigable Small World) kann die Anwendung nicht nur nach exakten Begriffen suchen, sondern auch nach semantisch ähnlichen Inhalten.
- KI-gestützte Antwortgenerierung: Die Anwendung kann mit einem lokalen LM Studio-Server kommunizieren, um natürlichsprachige Antworten auf Fragen zu generieren, die auf den indizierten Dokumenten basieren.
Technische Umsetzung
Die Anwendung kombiniert mehrere leistungsfähige Python-Bibliotheken:
- PyMuPDF (fitz): Für die PDF-Verarbeitung und Textextraktion
- Tesseract OCR: Für die optische Zeichenerkennung
- Sentence-Transformers: Für die Erzeugung von semantischen Embeddings
- HNSWlib: Für die effiziente Ähnlichkeitssuche in hochdimensionalen Räumen
- NiceGUI: Für das webbasierte User Interface
- LangChain: Für die Textaufteilung in sinnvolle Abschnitte
Besonders interessant ist die Architektur der Anwendung, die eine klare Trennung zwischen Backend-Verarbeitung (DocumentProcessor) und Frontend-Darstellung (DocumentProcessingUI) vorsieht. Die Verarbeitung läuft dabei in separaten Threads ab, sodass die Benutzeroberfläche stets responsiv bleibt.
Sicherheitsfeatures
Die Anwendung verfügt über mehrere Sicherheitsmechanismen:
- Session-Management: Mit Timeout und IP-Bindung
- Bruteforce-Schutz: Begrenzung der Login-Versuche
- Benutzerisolierung: Jeder Benutzer arbeitet in seinem eigenen Verzeichnis
- Admin-Rechte: Bestimmte Funktionen sind nur für Administratoren verfügbar
Praxisnutzen
Diese Lösung ist besonders nützlich für:
- Archivierung und Erschließung von gescannten Dokumenten
- Wissensmanagement in Unternehmen
- Recherche in großen Dokumentensammlungen
- Automatisierung von Dokumentenworkflows
Die Möglichkeit, die gesamte Verarbeitung lokal durchzuführen (auch die KI-Komponenten via LM Studio), macht die Lösung besonders attraktiv für Umgebungen mit hohen Datenschutzanforderungen.
Ausblick
Die modulare Architektur der Anwendung ermöglicht es, weitere Funktionen einfach zu integrieren. Geplante Erweiterungen könnten sein:
- Unterstützung weiterer Dateiformate
- Cloud-Integration für verteilte Dokumentensammlungen
- Erweiterte Visualisierungsmöglichkeiten für Suchergebnisse
- Automatisierte Kategorisierung von Dokumenten
Schreibe einen Kommentar