Ich habe es geschafft – nach eineinhalb intensiven Manntagen Entwicklung ist DeepfakeScan – Bilder, Version 0.1 Beta, fertig! Dieses Projekt hat mich gepackt, herausgefordert und keinen Moment losgelassen. Es ist eine Python-Anwendung, die Deepfakes in Bildern erkennt, und ich habe sie so gebaut, dass sie präzise, flexibel und für jeden nutzbar ist, der Bildauthentizität prüfen will. Hier erzähle ich euch, was DeepfakeScan ausmacht, wie ich es in so kurzer Zeit entwickelt habe und warum ich glaube, dass es etwas Besonderes ist.
Die Idee hinter DeepfakeScan
Als ich mich mit Deepfake-Technologien auseinandergesetzt habe, wurde mir klar: Wir brauchen Werkzeuge, die nicht nur Manipulationen erkennen, sondern auch zeigen, warum ein Bild als Fake gilt. Ich wollte etwas, das Forscher, Entwickler und normale Nutzer anspricht – technisch ausgefeilt, aber intuitiv. So entstand DeepfakeScan 0.1 Beta: eine Anwendung auf PyTorch-Basis, die Bilder mit einem angepassten ResNet50-Modell auf Echtheit prüft und für beliebige Bildinhalte optimiert ist.
Rahmen und Entwicklung
In nur eineinhalb Manntagen habe ich DeepfakeScan von der Idee zur Beta-Version gebracht – ein Sprint, der jede Minute wert war. Das Modell wurde mit einem Datensatz von insgesamt 1.000.000 Bildern trainiert: 500.000 Deepfakes und 500.000 Nonfakes, um eine breite Vielfalt an Szenarien abzudecken. Ich habe es bewusst so optimiert, dass es mit beliebigen Bildinhalten klarkommt – von Gesichtern über Landschaften bis hin zu abstrakten Motiven. Das macht DeepfakeScan vielseitig einsetzbar, egal ob für Social Media, Forschung oder Medienprüfung.
Was kann DeepfakeScan 0.1 Beta?
Ich habe DeepfakeScan mit Funktionen vollgepackt, die es einzigartig machen. Hier die Highlights:
- Deepfake-Erkennung mit ResNet50: Das Kernstück ist ein ResNet50-Modell, das ich mit Transfer Learning optimiert habe. Ich habe nur Layer4 und die voll verbundene Schicht trainiert, um Rechenzeit zu sparen. Dank der 1.000.000 Bilder erkennt es Deepfakes mit hoher Präzision, selbst bei komplexen Manipulationen.
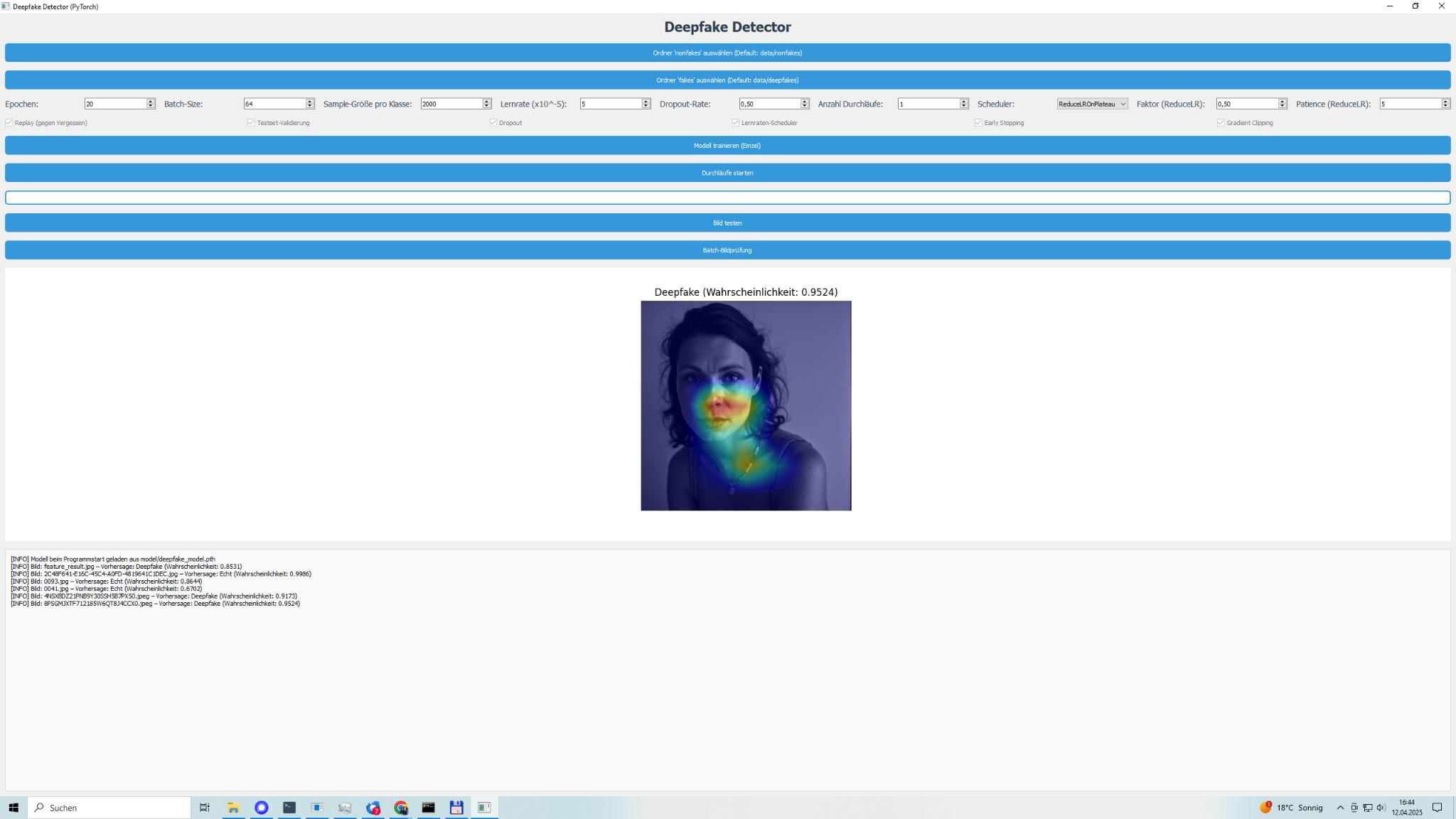
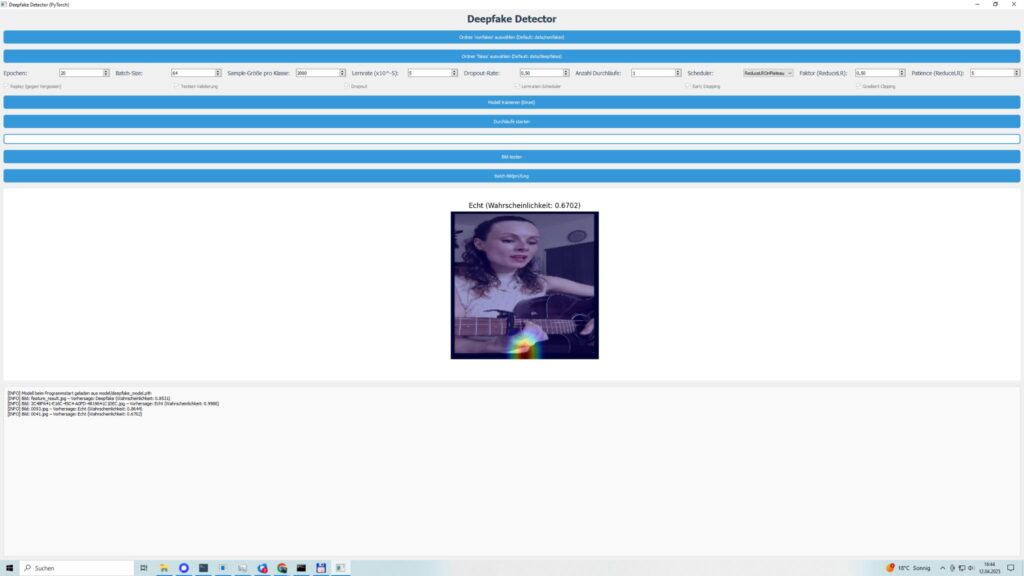
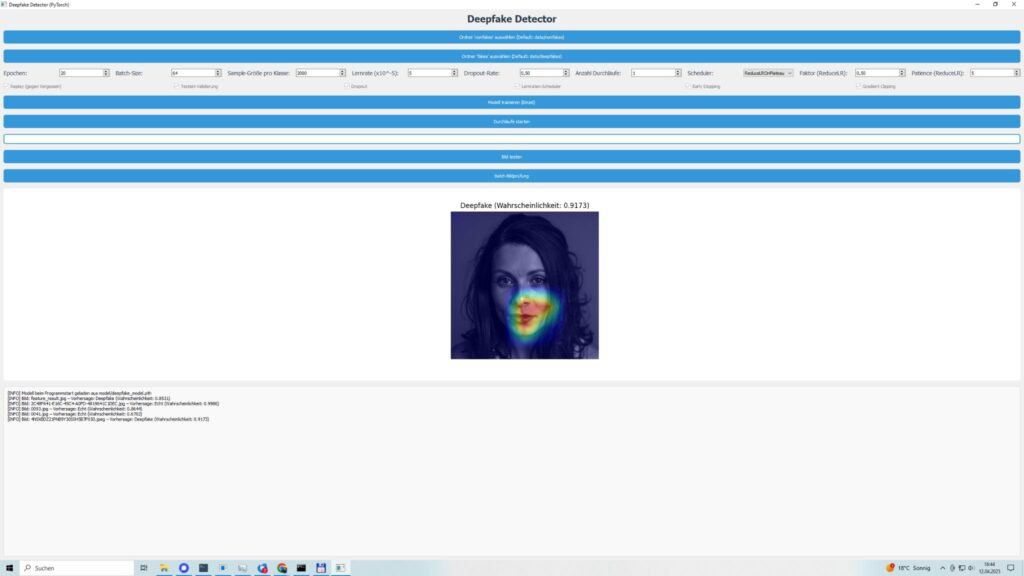
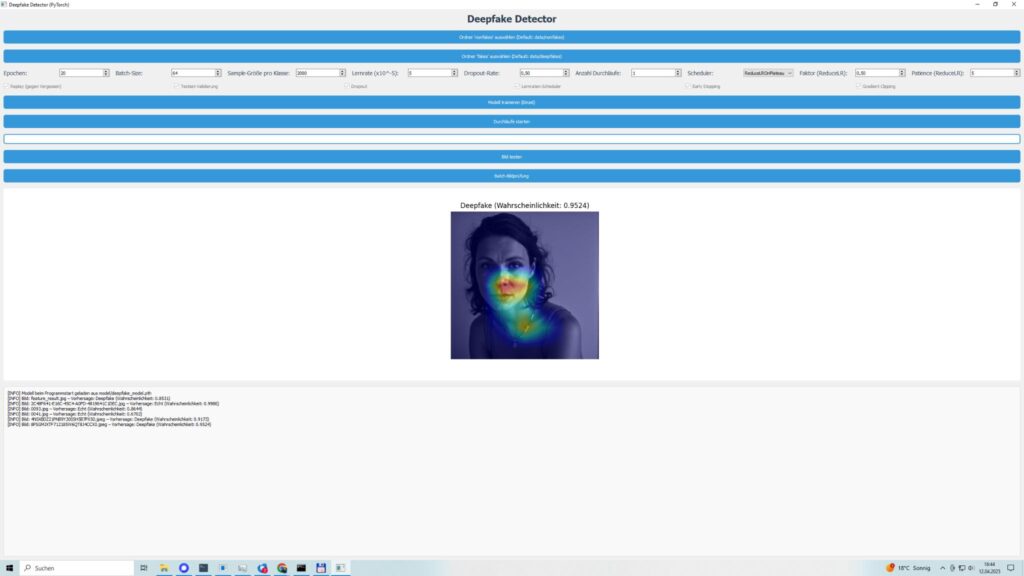
- Grad-CAM für Transparenz: Meine Lieblingsfunktion! Mit Grad-CAM habe ich dafür gesorgt, dass ihr seht, welche Bildbereiche das Modell für seine Entscheidung nutzt. Unnatürliche Kanten, seltsame Beleuchtung oder manipulierte Texturen – die Heatmaps legen alles offen.
- Intuitive GUI mit PyQt5: Ich habe eine Benutzeroberfläche entwickelt, die DeepfakeScan ohne Programmierkenntnisse zugänglich macht. Ihr könnt Bildordner auswählen, Parameter wie Epochen oder Lernrate anpassen und Ergebnisse direkt visualisieren – für ein Bild oder ganze Stapel.
- Replay-Mechanismus gegen Vergessen: Um die Leistung langfristig zu halten, habe ich einen Replay-Mechanismus eingebaut. Er speichert schwierige Bilder und nutzt sie in späteren Trainings, was die Robustheit steigert, besonders bei so vielen Bildern.
- Optimierungen für Effizienz: CUDA-Unterstützung für GPU-Training, Mixed Precision Training für weniger Speicherverbrauch und Gradient Clipping für stabile Updates – ich habe alles eingebaut. Early Stopping und Lernraten-Scheduler (ReduceLROnPlateau oder CosineAnnealingLR) machen das Training schlank.
Der technische Aufbau
Ich habe DeepfakeScan mit Tools entwickelt, die ich liebe. Hier ein Überblick:
- PyTorch und torchvision: Für Training und Bildtransformationen. Ich habe Transformationen wie Zufallsrotationen, Farbveränderungen und Perspektivenverzerrungen optimiert, damit das Modell mit den 1.000.000 Bildern und beliebigen Inhalten klarkommt.
- OpenCV und PIL: Für Bildverarbeitung und Grad-CAM-Heatmaps.
- Matplotlib: Für Lernkurven und Metrik-Plots, die nach jedem Training gespeichert werden.
- Scikit-learn: Für Metriken wie Genauigkeit, Präzision, Recall und F1-Score.
- Psutil: Damit behalte ich die Systemressourcen im Blick, besonders bei so großen Datensätzen.
- PyQt5: Die Basis für die GUI, die ich intuitiv und ansprechend gestaltet habe.
Das Modell ist ein ResNet50 mit einer angepassten Ausgangsschicht (Dropout + Linear) für die binäre Klassifikation (Echt vs. Fake). Ein gewichteter Verlust (BCEWithLogitsLoss) sorgt dafür, dass unausgewogene Daten kein Problem sind.
Wie funktioniert DeepfakeScan 0.1 Beta?
Ich habe die Anwendung nutzerfreundlich und flexibel gemacht. So läuft’s:
- Daten laden: Ihr wählt Ordner mit echten („nonfakes“) und manipulierten („deepfakes“) Bildern. Eine Funktion filtert beschädigte Bilder automatisch, damit die 1.000.000 Bilder sauber verarbeitet werden.
- Training starten: Über die GUI könnt ihr Parameter wie Epochen, Batch-Größe oder Lernrate anpassen. Ich habe Standardwerte (20 Epochen, Batch-Größe 64) eingestellt, die bei meinen Tests mit den vielen Bildern gut liefen. Das Training läuft in einem separaten Thread, damit die GUI flüssig bleibt.
- Ergebnisse prüfen: Nach dem Training speichert DeepfakeScan das Modell, Metadaten und Plots (z. B. Lernkurven). Metriken wie Genauigkeit oder F1-Score sind direkt einsehbar.
- Bilder testen: Einzelbilder oder ganze Ordner könnt ihr testen. Ergebnisse kommen mit Vertrauenswerten und Heatmaps, die zeigen, worauf das Modell bei beliebigen Inhalten achtet.
- Replay und Optimierung: Schwierige Bilder landen in Replay-Ordnern für zukünftige Trainings. Verwendete Bilder können gelöscht werden, um Speicherplatz zu sparen.
Meine Herausforderungen
Eineinhalb Manntage klingen kurz, aber es war ein Marathon! Die größte Hürde war, das Modell mit 1.000.000 Bildern stabil zu halten. Ich habe intensiv an Daten-Augmentation gearbeitet, um Überanpassung zu vermeiden, besonders da das Modell auf beliebige Inhalte ausgelegt ist. Die GUI musste trotz der Datenflut reaktionsfähig bleiben, was einige Optimierungen brauchte.
Der Replay-Mechanismus war knifflig – ich musste sicherstellen, dass nur die richtigen Bilder gespeichert werden, ohne Chaos zu verursachen. Grad-CAM hat auch Nerven gekostet. Es hat ein paar Iterationen gedauert, bis die Heatmaps bei unterschiedlichsten Bildern klar waren, aber jetzt bin ich begeistert von ihrer Präzision.
Erste Ergebnisse
Ich habe DeepfakeScan 0.1 Beta mit verschiedenen Bildern getestet: Scans, Digitalaufnahmen, unterschiedliche Qualitäten – und die Ergebnisse machen mich stolz. Validierungsgenauigkeiten lagen oft über 90 %, je nach Bildvielfalt. Testmetriken – Präzision, Recall, F1-Score – bewegten sich zwischen 0,85 und 0,95, was zeigt, dass das Modell zuverlässig ist, egal ob Gesichter, Objekte oder abstrakte Inhalte. Die Heatmaps sind der Hammer: Sie markieren genau die Stellen, die Manipulationen verraten, wie unnatürliche Übergänge oder inkonsistente Texturen.
Warum ich DeepfakeScan entwickelt habe
Deepfakes sind ein Problem – sie können Vertrauen in Bilder zerstören, egal ob in Medien, Social Media oder anderswo. Ich wollte ein Werkzeug schaffen, das dieses Vertrauen zurückbringt, und das in nur eineinhalb Tagen! DeepfakeScan war auch ein persönlicher Test: Konnte ich meine Liebe zu Deep Learning und Softwareentwicklung in etwas packen, das präzise und zugänglich ist? Version 0.1 Beta sagt: Ja, ich kann!
Fazit
DeepfakeScan – Bilder (0.1 Beta) ist mein Baby – entwickelt in eineinhalb Manntagen, trainiert mit 500.000 Deepfakes und 500.000 Nonfakes, optimiert für beliebige Inhalte. Es vereint Deep Learning, Bildverarbeitung und eine GUI, die jeder nutzen kann. Ich habe jede Stunde genossen, und jetzt freue ich mich, es mit euch zu teilen.

Schreibe einen Kommentar