Da synthetische Stimmtechnologien wie Deepfakes immer ausgefeilter werden, wird die Verifizierung der Sprecheridentität zunehmend wichtiger. Von der Absicherung sprachgesteuerter Systeme bis zur Erkennung betrügerischer Audios – die Nachfrage nach zuverlässigen Tools steigt. In diesem Beitrag stellen wir VoiceGuard 0.1B vor, eine Beta-Version einer Python-Anwendung zur Sprecher-Verifizierung, die Audios mit gespeicherten Stimm-Embeddings vergleicht. Mit dem SpeechBrain-Toolkit, einer PyQt5-Oberfläche und fortschrittlicher Audiovorverarbeitung legt diese Beta-Version eine solide Grundlage. Lassen Sie uns die Funktionen, Architektur und Möglichkeiten erkunden.
Die wachsende Notwendigkeit der Sprecher-Verifizierung
Fortschritte in der KI-gestützten Audiosynthese – etwa durch Modelle wie WaveNet – ermöglichen es, Stimmen täuschend echt nachzubilden. Dies eröffnet Möglichkeiten für Missbrauch, wie Identitätsdiebstahl oder Desinformation. Sprecher-Verifizierung, die prüft, ob ein Audio zu einer bekannten Stimme passt, ist eine wichtige Abwehr. VoiceGuard 0.1B adressiert diese Herausforderung in der Beta-Phase mit maschinellem Lernen und einer benutzerfreundlichen Oberfläche.
Was macht VoiceGuard 0.1B?
VoiceGuard 0.1B ist ein Python-Tool zur Sprecher-Verifizierung in der frühen Beta-Phase (Version 0.1B). Hier ein Überblick:
- Stimmregistrierung: Erstellt Stimm-Embeddings aus mehreren Audios mit dem SpeechBrain ECAPA-TDNN-Modell.
- Embedding-Management: Speichert Embeddings als .pt-Dateien, konvertiert sie in Base64- oder Hash-Formate (z. B. SHA-512) und lädt sie wieder.
- Verifizierung: Vergleicht Test-Audios mit gespeicherten Embeddings und berechnet Identitätsscores mit anpassbarer Vorverarbeitung.
- GUI-Erlebnis: Bietet eine PyQt5-Oberfläche zum Registrieren, Verifizieren und Visualisieren von Ergebnissen.
- Audio-Wiedergabe: Ermöglicht das Abspielen von Test-Audios direkt in der App.
Als Beta-Version ist es ein laufendes Projekt, zeigt aber bereits eine solide Basis.
Kernkomponenten von VoiceGuard 0.1B
1. Sprecher-Verifizierungsmodell
VoiceGuard nutzt das ECAPA-TDNN-Modell von SpeechBrain, vortrainiert auf dem VoxCeleb-Datensatz (VoxCeleb). Die Funktion ensure_model lädt erforderliche Dateien von Hugging Face manuell herunter, falls nötig.
2. Stimmregistrierung und Embedding-Erstellung
Die Klasse EmbeddingThread übernimmt die Registrierung:
- Nutzer wählen Audiodateien (WAV, MP3, AAC) eines Sprechers.
- Embeddings werden mit encode_batch extrahiert und gemittelt, um ein Stimmprofil zu erstellen, das als .pt-Datei gespeichert wird.
3. Embedding-Management mit Hashing
Einzigartige Features sind:
- Hash-Konvertierung: convert_to_hash kodiert .pt-Dateien in Base64, SHA-512 oder SHA-128.
- Hash-Laden: load_embedding_from_hash dekodiert Base64 zurück in .pt-Dateien.
Diese experimentellen Funktionen bieten Flexibilität in der Beta-Phase.
4. Audiovorverarbeitung und Verifizierung
VerificationThread vergleicht Test-Audios mit Referenz-Embeddings, mit Optionen wie:
- Stille entfernen: Via Torchaudio-VAD.
- Lautstärke normalisieren: Skaliert auf [-1, 1].
- Frequenzfilter: Bandpass (300–3400 Hz).
- Rauschunterdrückung: Subtrahiert Rauschen aus Spektrogrammen.
Der Identitätsscore wird mit einem anpassbaren Schwellenwert (Standard: 0.9) bewertet.
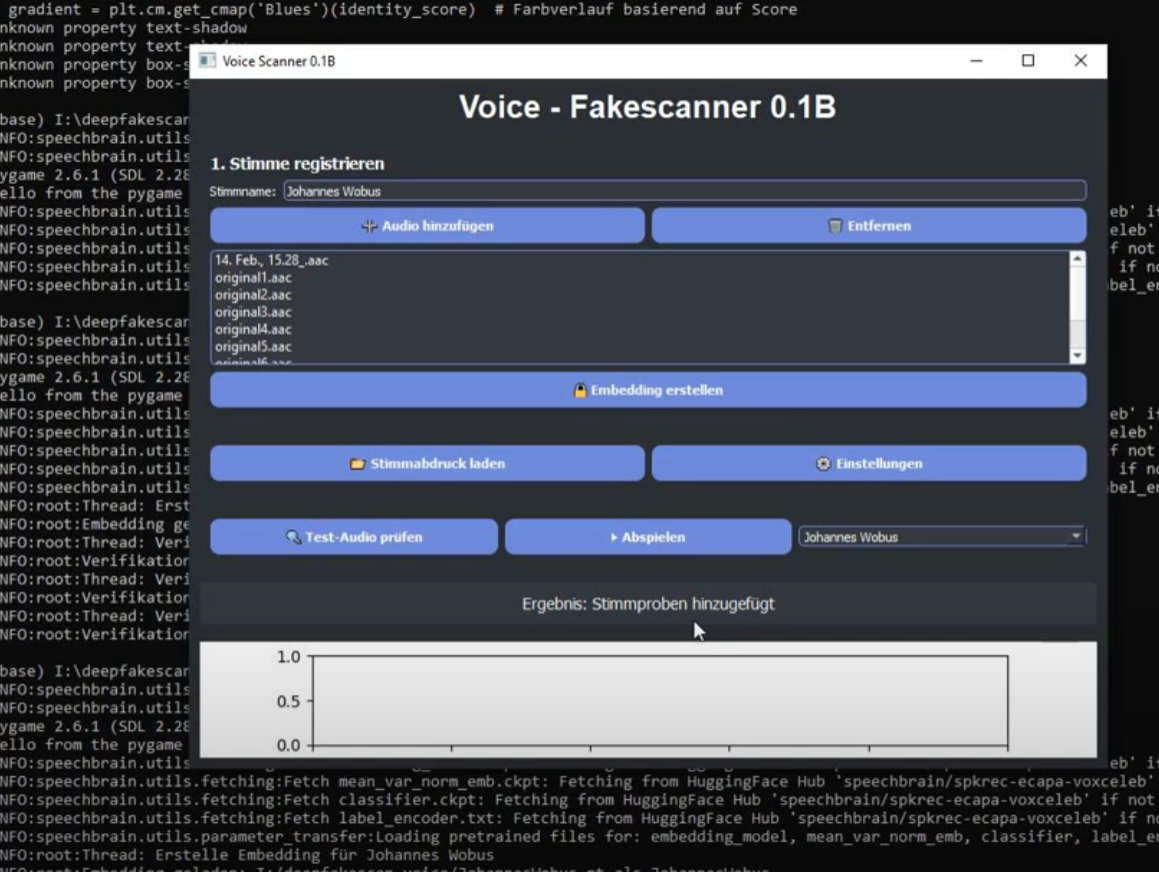
5. Grafische Benutzeroberfläche
Die PyQt5-GUI bietet:
- Registrierung: Audios hinzufügen/entfernen, Embeddings speichern.
- Tools: Embeddings laden, in Hash umwandeln, Einstellungen anpassen.
- Verifizierung: Test-Audio prüfen, Ergebnisse mit Matplotlib-Plots anzeigen.
Wie es funktioniert: Ein Beispiel
- Stimme registrieren: Laden Sie drei Clips von „Alice“ und speichern Sie das Embedding als alice.pt.
- Embedding laden: Laden Sie alice.pt als aktives Profil.
- Verifizieren: Wählen Sie ein Test-Audio, aktivieren Sie Rauschunterdrückung, und erhalten Sie einen Score von 0,92 (bestätigt als Alice).
- Abspielen: Hören Sie das Test-Audio direkt in der App.
Warum sticht VoiceGuard 0.1B heraus?
- Vorverarbeitung: Flexibilität wie Rauschunterdrückung.
- Hashing: Base64- und SHA-Unterstützung.
- GUI: Benutzerfreundlich für Einsteiger.
- Open Source: Basierend auf SpeechBrain.
Verbesserungspotenzial
Die Beta-Version könnte erweitert werden durch:
- Spoof-Erkennung: Anti-Spoofing-Modelle integrieren.
- Echtzeit: Mikrofon-Eingabe via PyAudio.
- Modellanpassung: Feintuning des Modells.
Fazit
VoiceGuard 0.1B ist ein vielversprechendes Beta-Tool für Sprecher-Verifizierung mit innovativen Funktionen und einer zugänglichen Oberfläche. Es ist ideal für Forschung und Sicherheit. Testen Sie die Beta-Version und gestalten Sie ihre Zukunft mit!
Schreibe einen Kommentar