In einer Zeit, in der künstliche Intelligenz hyperrealistische Audio-Deepfakes erzeugen kann, ist die Unterscheidung zwischen echtem und synthetischem Material eine große Herausforderung. Von Desinformationskampagnen bis hin zu Identitätsbetrug – die Risiken sind enorm. Glücklicherweise bieten Fortschritte im maschinellen Lernen und in der Audiosignalverarbeitung leistungsstarke Werkzeuge, um dieser Bedrohung entgegenzuwirken. In diesem Blogbeitrag stellen wir eine ausgefeilte Python-basierte Anwendung vor – aktuell in der Beta-Version –, die Deepfake-Audio mithilfe einer segmentbasierten Feature-Extraktion, dualer Modellklassifikation (XGBoost und LightGBM) und einer intuitiven grafischen Benutzeroberfläche mit PyQt5 erkennt. Ob Sie Data Scientist, Audioingenieur oder Technik-Enthusiast sind, dieser tiefgehende Einblick führt Sie durch die Architektur, Funktionalität und das Potenzial dieser innovativen Beta-Lösung.
Der Aufstieg der Audio-Deepfakes
Deepfakes – KI-generierte Medien, die echte Stimmen oder Bilder nachahmen – haben in den letzten Jahren dank Tools wie WaveNet und VALL-E enorme Fortschritte gemacht. Während diese Technologien beeindruckende Innovationen zeigen, bergen sie auch Risiken, wenn sie missbraucht werden. Stellen Sie sich vor, ein Betrüger imitiert Ihre Stimme, um eine Banktransaktion zu autorisieren, oder eine gefälschte politische Rede löst Chaos aus. Um dem entgegenzuwirken, benötigen wir robuste Erkennungssysteme, die Audio auf granularer Ebene analysieren. Genau hier setzt unsere Beta-Anwendung an.
Was macht diese Beta-Version?
Dieses Python-Skript ist eine vollständige End-to-End-Pipeline zur Erkennung von Deepfake-Audio in der Beta-Phase. Hier ein Überblick über ihre Fähigkeiten:
- Feature-Extraktion: Analysiert Audiodateien, indem sie in kleine Segmente (Standard: 10 Millisekunden) zerlegt und 48 verschiedene Audio-Merkmale wie Spektralzentroide, MFCCs und harmonische Verhältnisse extrahiert.
- Datenbank: Speichert die extrahierten Merkmale in SQLite-Datenbanken für Deepfakes und Nicht-Deepfakes, was effizientes Training und Analyse ermöglicht.
- Modelltraining: Trainiert zwei leistungsstarke Machine-Learning-Modelle – XGBoost und LightGBM – mit den extrahierten Merkmalen, unterstützt durch GPU-Beschleunigung via CUDA oder OpenCL.
- Vorhersage: Klassifiziert neue Audiodateien als „Deepfake“ oder „Kein Deepfake“ basierend auf segmentweisen Vorhersagen, mit gemittelten Ergebnissen für ein finales Urteil.
- Visualisierung & Berichte: Bietet eine elegante PyQt5-basierte GUI mit detaillierten Visualisierungen (z. B. Heatmaps, Lernkurven) und exportiert Berichte als PDFs.
Schauen wir uns die einzelnen Komponenten dieser Beta-Version genauer an.
Kernkomponenten der Pipeline
1. Audio-Feature-Extraktion
Das Herzstück dieser Beta-Anwendung ist die Fähigkeit, 48 Audio-Merkmale aus kurzen Klangsegmenten zu extrahieren. Mit Bibliotheken wie Librosa und Torchaudio verarbeitet der Code Audiodateien (z. B. WAV, MP3) und berechnet Merkmale wie:
- Zeitliche Merkmale: Durchschnittliche Amplitude, Null-Durchgangsrate, Root-Mean-Square-Energie (RMSE).
- Spektrale Merkmale: Spektralzentroid, Bandbreite, Rolloff, Ebenheit und Kontrast.
- Harmonische Merkmale: Harmonisches-Rausch-Verhältnis (HNR), Tonnetz und Grundfrequenz.
- Statistische Merkmale: Schiefe, Kurtosis, Energieentropie.
- Mel- und Chroma-Merkmale: Mel-Frequenz-Cepstrum-Koeffizienten (MFCCs), Chroma-Varianz und Mel-Spektrogramm-Statistiken.
Für jedes 10-ms-Segment berechnet die Funktion extract_48_features diese Metriken sorgfältig und bietet Fehlerbehandlung für Ausnahmen (z. B. stille Segmente oder NaN-Werte).
2. Hardware-Beschleunigung
Um große Datenmengen effizient zu verarbeiten, unterstützt diese Beta-Version Hardware-Beschleunigung:
- CUDA: Nutzt NVIDIA-GPUs via PyTorch, falls verfügbar.
- OpenCL: Verwendet PyOpenCL für breitere GPU-Kompatibilität.
- CPU-Fallback: Greift auf CPU-Verarbeitung zurück, wenn keine GPU erkannt wird.
Die Funktion select_device wählt dynamisch die beste Plattform basierend auf Benutzerpräferenz und Hardware-Verfügbarkeit.
3. Datenmanagement mit SQLite
Extrahierte Merkmale werden in zwei SQLite-Datenbanken gespeichert: deepfakes.db für synthetisches Audio und non_deepfakes.db für echtes Audio. Die Klasse FeatureExtractionThread führt diesen Prozess im Hintergrund aus und protokolliert Fehler (z. B. ungültige Segmente).
4. Machine-Learning-Modelle
Die Beta-Anwendung trainiert zwei erstklassige Gradient-Boosting-Modelle:
- XGBoost: Bekannt für Geschwindigkeit und Genauigkeit (XGBoost-Dokumentation).
- LightGBM: Optimiert für große Datensätze und schnelles Training (LightGBM-Dokumentation).
Die Funktion train_models teilt die Daten in Trainings- und Testsets, passt die Modelle an und bewertet sie mit Metriken wie Genauigkeit, AUC-ROC und Lernkurven.
5. Deepfake-Vorhersage
Bei der Analyse einer neuen Audiodatei extrahiert PredictionThread Merkmale, gibt sie an die trainierten Modelle weiter und berechnet segmentweise Wahrscheinlichkeiten (0 = kein Deepfake, 1 = Deepfake). Das endgültige Ergebnis mittelt die Ausgaben von XGBoost und LightGBM.
6. GUI und Berichterstellung
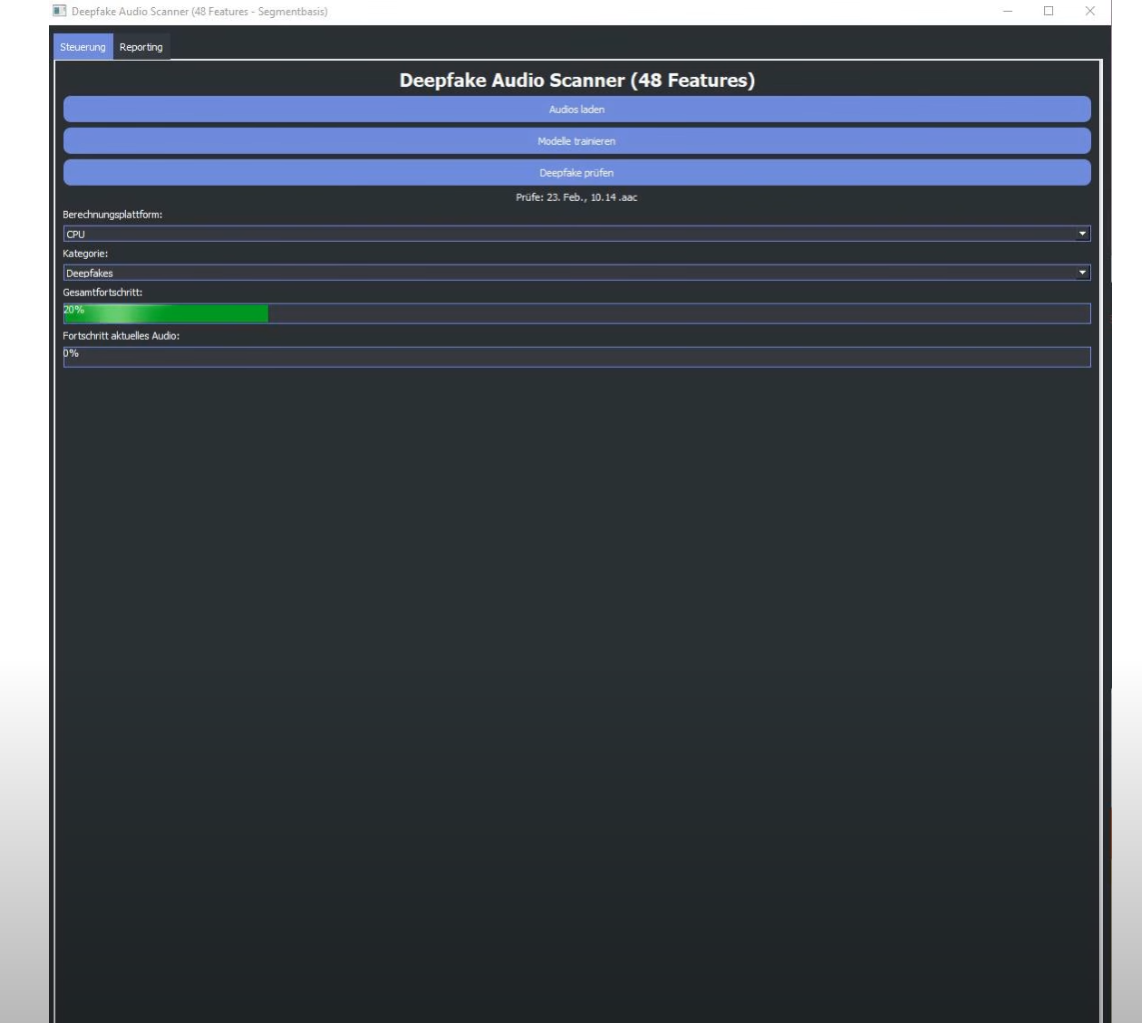
Die Klasse DeepfakeApp, basierend auf PyQt5, bietet eine benutzerfreundliche Oberfläche mit zwei Tabs:
- Steuerung: Audios laden, Modelle trainieren, Hardware wählen (CPU/GPU), Fortschritt überwachen.
- Berichterstellung: Zeigt detaillierte Analyseergebnisse wie Balkendiagramme, Heatmaps und Feature-Verteilungen, exportierbar als PDF via ReportLab.
Wie es funktioniert: Ein Beispiel
- Audios laden: Sie laden 10 Audiodateien (5 Deepfakes, 5 echte) über die GUI.
- Feature-Extraktion: Die Beta-App extrahiert 48 Merkmale pro 10-ms-Segment und speichert sie in Datenbanken.
- Training: Sie klicken auf „Modelle trainieren“, und die App erstellt XGBoost- und LightGBM-Klassifikatoren.
- Vorhersage: Sie wählen eine neue Audiodatei. Die App zeigt eine 75%-ige Deepfake-Wahrscheinlichkeit mit Visualisierungen.
- Export: Sie speichern den Bericht als PDF.
Warum sticht diese Beta-Version heraus?
- Granulare Analyse: Segmentbasierte Extraktion erfasst subtile Anomalien.
- Doppelmodell-Ansatz: XGBoost und LightGBM erhöhen die Robustheit.
- Visualisierung: Interaktive Plots erleichtern die Interpretation.
- Skalierbarkeit: GPU-Unterstützung und Threading verarbeiten große Datenmengen.
Potenzielle Verbesserungen
Die Beta-Version ist vielversprechend, könnte aber erweitert werden:
- Feature-Erweiterung: Integration von Rohwellenform-Embeddings.
- Echtzeit-Erkennung: Anpassung für Streaming-Audio.
- Modelltuning: Hyperparameter-Optimierung mit Optuna.
Fazit
Diese Beta-Anwendung zeigt, wie maschinelles Lernen, Audioverarbeitung und UI-Design zusammen Deepfakes bekämpfen können. Mit 48 Merkmalen, leistungsstarken Modellen und einer zugänglichen GUI ist sie ein wertvolles Werkzeug für Forschung und Sicherheit.
Schreibe einen Kommentar